 OPEN EDGE AI
OPEN EDGE AIOpen Edge AI for Defense
Mente AI allows people to access powerful AI tools even in environments with low-connectivity
Keep inferring. Always.
Immediately access your model on any device where your app is deployed. Continuously train your models without disruption.Lighter, faster, better.
State-of-the-art automatic workflows for data dimensionality reduction. Deploy easily on premise, hybrid or cloud.Democratize AI.
Free to deploy as part of any application. Yes. Free.01 | Automate AI Reduction
Optimize your models for edge deployment and validate model performance02 | Infer at the Edge
No connectivity, no problem. Inference delivered based on cashed ML lite models03 | Cluster with Ease
Share resources on multiple devices for caching, training, inference and load balancingOpen Model Optimization Architecture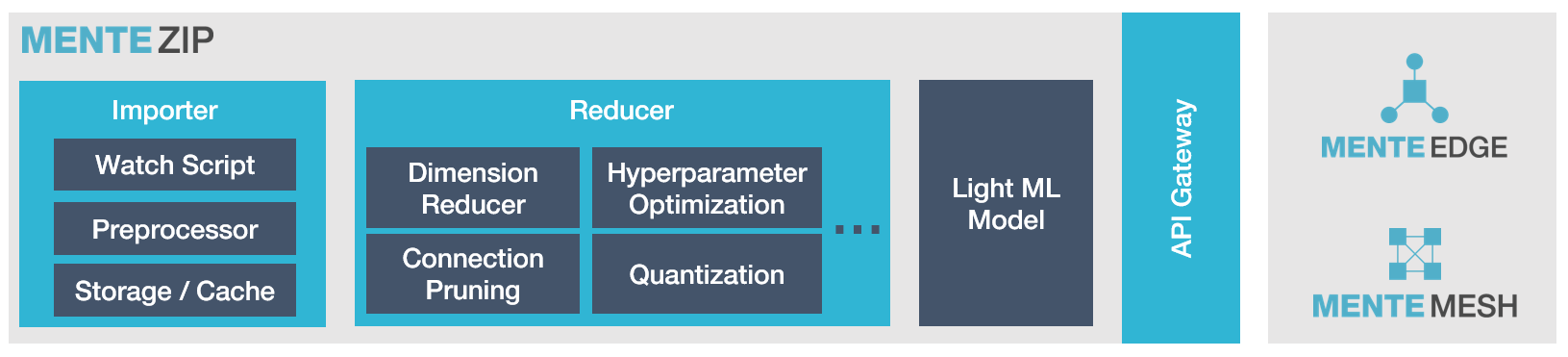

 Platform for automated model reduction and management
Platform for automated model reduction and management
 Application module for contextual model sourcing and interface
Application module for contextual model sourcing and interface
 Module extension for distributed nodes resource sharing
Module extension for distributed nodes resource sharing
Platform for automated model reduction and managementApplication module for contextual model sourcing and interfaceModule extension for distributed nodes resource sharingTrim models to accelerate training algorithm
Skim off low-quality data
Shrink complex models automatically
Reduce noise and speed delivery
Lighten data-dimension, simply and easy
Reduce Model ComplexityTest and select multiple reducer techniques to produce optimized reduced models
Control OutcomesSelect minimum acceptable degradation thresholds and fidelity of the model.
Explain PerformanceDeploy with confidence showing model performance and effectiveness.
Deliver inference always
Save power, processing and hosting
Enhance intelligent application development
Secure AI on device, even with no connectivity
Accelerate inference speed, even with low connectivity
Integrate with EaseSuper simple integration into any application via SDK or package
Increase AutonomyNo connectivity requirement. Inference delivered based on cashed ML lite models
Train at the EdgeUpdate the performance of your light model on the edge device
Combine a cluster of user resources
Share data between edge devices
Distribute power and processing
Syndicate inference results
Manage output and outcomes
Increase AccuracyLeverage several edge devices power and computational resources to improve results
Accelerate CollaborationShare results in a common interactive intelligent human machine interface
Validate DataUse collective data inputs for continued model test and validation
 Bringing AI to the Edge
Bringing AI to the Edge